Database
SQL
- Structured Query Language (SQL)
Language
CTE (Common Table Expression)
- A temporary named query that exists only during the execution of that specific command.
- Syntax: Defined using the WITH keyword.
CTAS (Create Table As Select)
- Command used to create a new, permanent table based on the results of a SELECT statement. It combines the table creation and data insertion steps into one efficient move.
- Syntax: CREATE TABLE table_name AS SELECT …
Drop
-
Drop table:
DROP TABLE table_name; -
Drop partition:
Alter TABLE table_name DROP IF EXISTS PARTITION (partition_name=partition);
Window Functions
-
General:
SELECT column_name1, window_function(column_name2) OVER ([PARTITION BY column_name3] [ORDER BY column_name4]) AS new_column FROM table_name; -
Ranking:
Salary RANK() DENSE_RANK() ROW_NUMBER() 50000 1 1 1 50000 1 1 2 30000 3 2 3 20000 4 3 4 10000 5 4 5
RDBMS
- Relational Database Management Systems (RDBMS).
- The RDBMS handles the “Front Line”. Hadoop handles the “History”. When a user buys an item on your website, that transaction goes into an RDBMS (MySQL). It needs to be instant, and it needs to be perfectly accurate (you can’t accidentally charge someone twice). Once a day, your company likely runs a job that “exports” all the transactions from the MySQL RDBMS and “dumps” them into Hadoop (HDFS).
Transaction
- ACID Properties:
- Atomicity: Atomicity ensures that a transaction is treated as a single unit of work, and either all operations within the transaction are successfully completed, or none of them are.
- Consistency: Consistency ensures that a transaction brings the database from one valid state to another. The database must remain in a valid state before and after the transaction.
- Isolation: Isolation ensures that the operations within a transaction are invisible to other transactions until the transaction is complete.
- Durability : Durability ensures that once a transaction is committed, its changes are permanent and will survive any system crash or failure.
MySQL
- OLTP (Online Transaction Processing). Looking up one specific row very fast.
- Spark / Presto /Doris are all OLAP (Online Analytical Processing).
- A classic Relational Database.
PostgreSQL
NoSQL
- Document-Based: JSON-like documents. MongoDB
- Key-Value Store: Key-Value pairs. Redis
- Column-Oriented: Columns instead of rows: HBase
Key-Value Store
Redis
Storage
Kubernetes
- Kubernetes (k8s)
- While YARN was built specifically to manage Big Data jobs (like Hadoop and Spark), Kubernetes was built to manage Containers (like Docker). Kubernetes is an orchestrator that automates the deployment, scaling, and management of “containerized” applications.
introduction-to-kubernetes-k8s
Cloud
- Large-scale data centers owned by companies like Amazon (AWS), Google (GCP), or Microsoft (Azure). Instead of your company buying physical servers, bolting them into a rack, and plugging in the power cables, they “rent” virtual versions of those resources over the internet.
- On-Premise: (Private Cloud)
- On-Cloud: (Public Cloud)
Hadoop
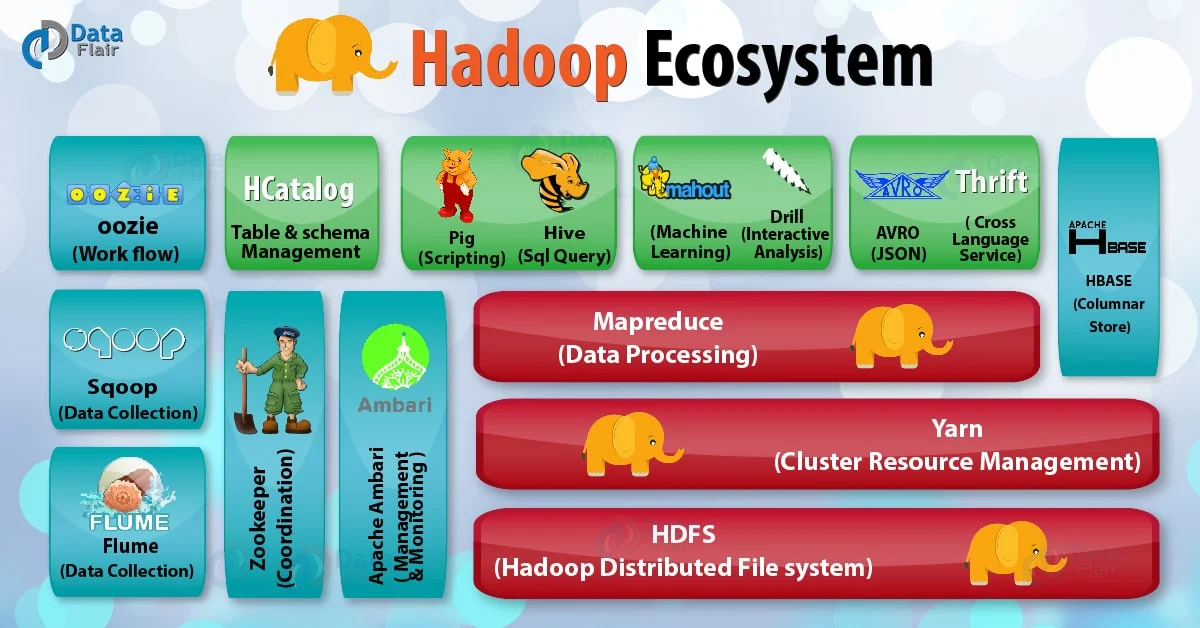

HDFS
- Hadoop Distributed File System (HDFS)
YARN
- Yet Another Resource Negotiator (YARN)
- Acts like the Operating System of Hadoop, managing resources (CPU, RAM) and scheduling jobs so that different engines (not just MapReduce, but also Spark or Hive) can run on the same data at the same time.
Hive
- Hive was created (originally by Facebook) to allow people who know SQL to work with data in Hadoop. Without Hive, you’d have to write complex Java code to count rows. It turns SQL into a series of jobs that run on Hadoop. It alse stores Metadata.
Engines
MapReduce
- MapReduce breaks every big data problem into exactly two rigid phases:
- Map: Each node processes a local piece of data and turns it into “key-value pairs” (e.g., counting words in a single document).
- Reduce: The system shuffles all identical keys to the same node, where they are aggregated (e.g., summing up all instances of the word “apple”).
- Word Count Example:
-
The Map Phase (Local Processing)
Input: “Apple Banana Apple”
Mapper Output: (Apple, 1), (Banana, 1), (Apple, 1)
-
The Shuffle & Sort Phase (The Bridge)
Input: Pairs from all over the cluster.
Output to Reducer A: (Apple, 1), (Apple, 1)
Output to Reducer B: (Banana, 1)
-
The Reduce Phase (Aggregation)
Reducer A Calculation: 1 + 1 = 2
Final Output: (Apple, 2), (Banana, 1)
-
Spark
- Difference between mapreduce and spark:
- MapReduce is “Disk-First,” Spark is “Memory-First.”
- In-Memory Processing: Spark keeps data in RAM between different stages of a job. It doesn’t write to the disk unless it absolutely has to (e.g., during a Shuffle or if it runs out of memory).
- DAG vs. Linear: MapReduce is a linear “Map -> Reduce” chain. Spark creates a DAG (Directed Acyclic Graph). This allows Spark to look at your entire query and optimize the path.
- Speed: Because it avoids constant disk I/O, Spark is often 10x to 100x faster than MapReduce for many workloads.
Dataframe
- DataFrame: DataFrame = RDD + Schema
-
RDD (Resilient Distributed Dataset):
When you call .rdd on a DataFrame, you are accessing the underlying collection of Row objects distributed across the cluster. Unlike a DataFrame, an RDD does not know anything about the names of the columns or the types of data inside it until it’s actually processed. It is “unstructured” compared to the DataFrame API.
- The Schema: the metadata that defines the structure of your data. If the RDD is the “content,” the Schema is the “table definition.” It contains Column Names, Data Types, and Nullability.
API
- spark.sql(): The result is a DataFrame.
- Export data:
- saveAsTextFile: takes the data inside an RDD and writes it out to a storage system as plain text files.
- dataframe.write.csv(): If you have columns and types, use this.
Web UI
Optimization
-
Data skew: a condition in distributed computing where data is not distributed evenly across the cluster. In a distributed system, your job is only as fast as its slowest task. Power Users/Hot Keys and Null Values may lead to this.
-
Threshold configuration (spark.sql.autoBroadcastJoinThreshold)
If the statistics for one of the tables show it is smaller than this value, the engine will automatically plan a Broadcast Hash Join.
-
Broadcast Hash Join (BHJ):
One of the datasets (the “small” one) is collected at the driver and then sent (broadcast) to every worker node in the cluster.
Pros: Extremely fast; eliminates the need for shuffling and sorting.
Cons: Risk of Out of Memory (OOM) errors if the broadcast table is too large.
-
Sort Merge Join (SMJ):
Both datasets are re-partitioned (sent to the same node) across the cluster based on the join key.
Pros: Highly scalable and robust; can handle massive datasets; does not require fitting an entire table into memory.
Cons: Slower due to the high cost of shuffling data over the network and the CPU cost of sorting.
Engineering praticals
-
Backfilling/Re-triggering tasks based on soft dependencies may lead to data inconsistency between previous and current results.
Because when upstream tasks is not ready is not ready in the same/current day but is ready when re-running, the inconsistency/discrepancies may appear.
Presto
- a “Massively Parallel Processing” (MPP) SQL engine. It was designed by Facebook specifically to make interactive queries lightning fast.
- Memory-to-Memory: Presto was built from the ground up to be “in-memory.” It streams data from the disk directly through the network to the next processing stage without ever stopping to write “checkpoints” to the disk.
- No “Startup” Overhead: When you run a Spark job, YARN often has to “request” containers, start up a Spark context, and coordinate executors. Presto is usually a “long-running” service—it’s already awake and waiting for your command, so it starts immediately.
- Optimized for SQL: Spark is a general-purpose engine (it can do ML, Streaming, etc.). Presto is a SQL specialist. It does one thing—SQL—and it does it perfectly.
- The “All or Nothing” Problem: If a Presto query is running on 100 nodes and one node fails or runs out of memory, the entire query fails. Presto does not have “fault tolerance” for individual tasks.
- The “OOM” (Out of Memory) Safety: Because Presto keeps everything in RAM, a “too large” query will crash the Presto worker. Your platform likely has a Rule Engine that says: “If this query looks like it will touch more than X terabytes, send it to Spark so it doesn’t crash the Presto cluster.”
Doris
- Apache Doris is a modern, real-time data warehouse designed for OLAP (Online Analytical Processing). In the “Data Warehouse” family, if Hive is the old, reliable storage vault, Doris is the high-speed trading floor.
- When you use Spark or Presto, they are Compute-only engines. Doris, however, follows the Storage-Compute Coupled principle. It owns the physical disks and dictates exactly how every byte is written.
- Doris is its own independent system that is designed to replace the need for both RDBMS and Hadoop for analytical work.
- Doris simplifies the “distributed system” concept into two main components:
- Frontend (FE): The “Brain.” It handles user connections, parses your SQL queries, and creates the plan for how to get the data.
- Backend (BE): The “Muscle.” These live on your physical Blades. They store the actual data and do the heavy lifting of calculating sums, averages, and joins.