LLM
LLM Models
Transformer
- Use translation tasks as an example.
- The input (encoder input) and output (decoder input) are both sentences. Each word is a vector $\in \R^d$, d is the model dimension (embedding dimension). So the input and output are matrices $\in \R^{l \times d}$, l is the sentence length (word numbers in a sentence).
- The output probabilities (label) is a vetor $\in \R^l$ instead of a single number. The output and the Label are the same sentence, just offset (right) by one position, which is called Teacher Forcing.
-
Example: To translate “I love cats” (English) to “Me gustan los gatos” (Spanish), your training data consists of three specific tensors: Encoder Input: [I, love, cats,
] Decoder Input: [
, Me, gustan, los, gatos] Label (Target): [Me, gustan, los, gatos,
] -
The encoder attention layer is the original one. The Masked attention layer is applied with mask to block out the upper triangle in the attention score matrix. (When the model is processing the word at position $i$, the mask blocks out all positions from $i+1$ to $n$.)
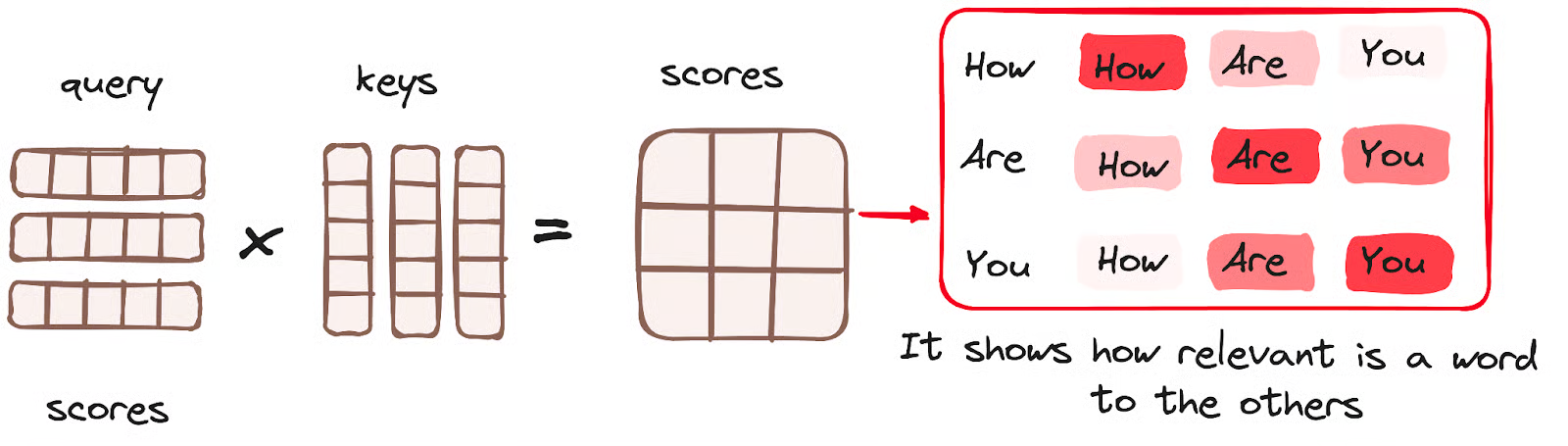
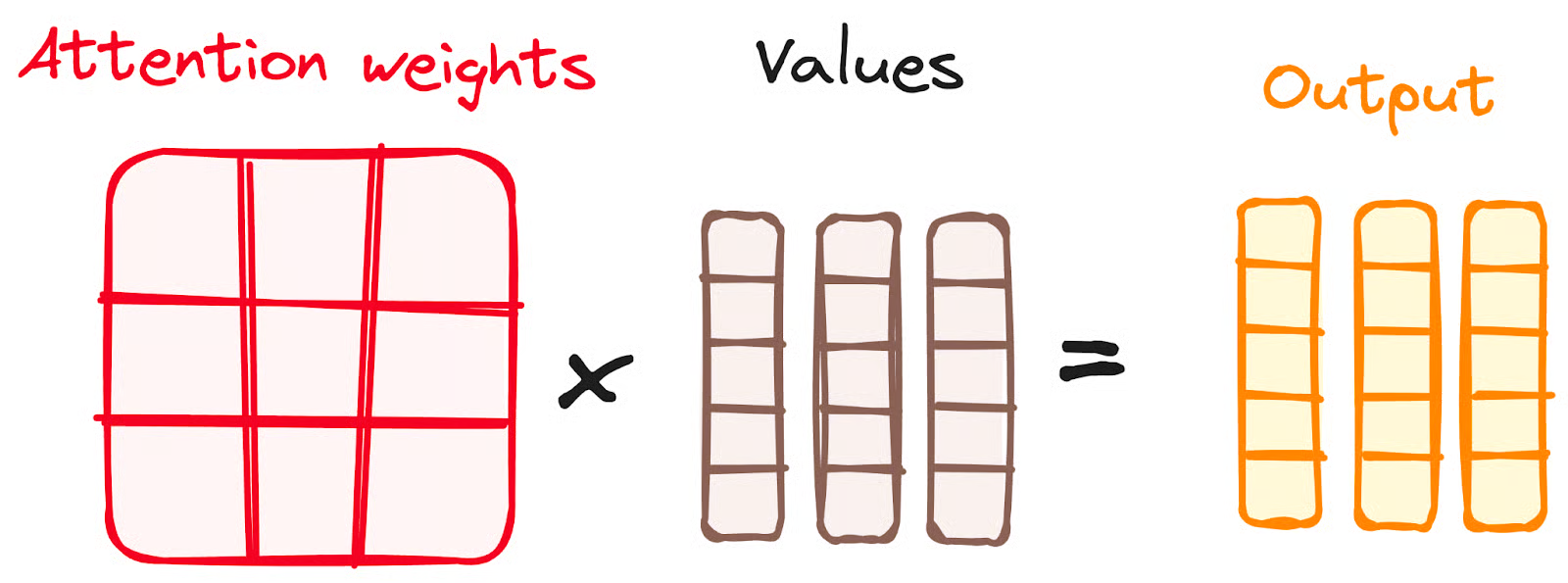
This figure is wrong. the values should be 3 $\times$ 5 (also the output), otherwise it violates the matrix multiplication rule.
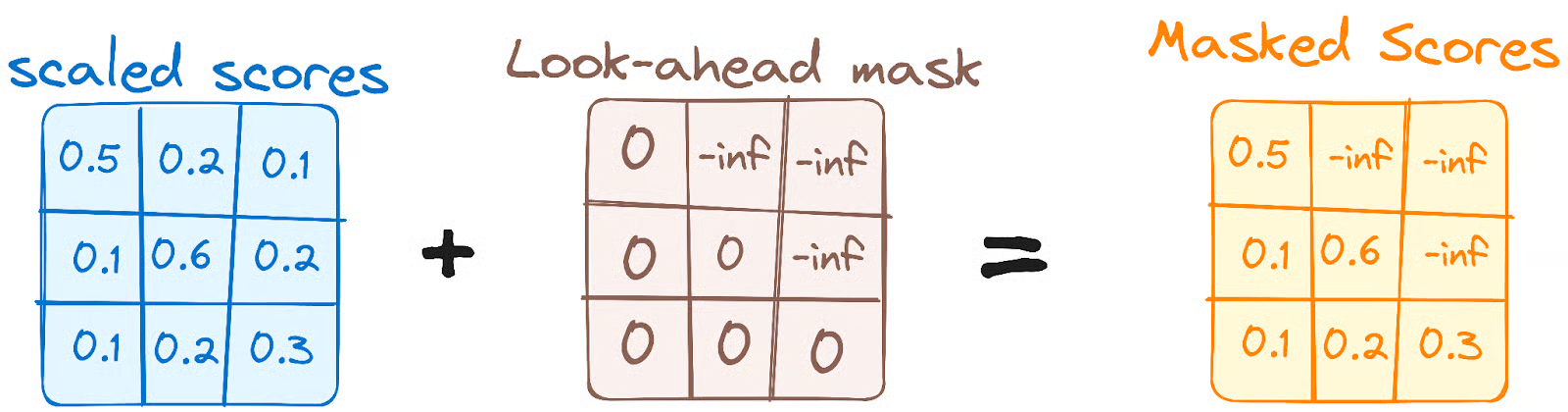
- The masking mechanism both exist in training and inference. (the code and structure is the same between training and inference.)
- The encoder-decoder attention layer in decoder uses the output of the masked attention layer in decoder as the query and the output of encoder as the key and the value.
- The entire sentence is feeded to the decoder input in training, while the tokens are generated one by one and feed back to the decoder as input auto-regressively during inference. But note that the label array is always the same shape! (as well as the input and output.) There might be a extra process to feed those output tokens back.
- The query would be shorten (without the bottom part) during the inference, so the socre matrix would only have the several upper rows being non-zero. Then multiplied by the values, the output will also be shorten (without the bottom part), the same length as the query. Considering the Teacher Forcing method, the last word output would be the predition of the next word!
- GPT only uses self-attention in the decoder (with masking). It does not use encoder-decoder attention. BERT only uses self-attention in the encoder. It does not use encoder-decoder attention either. Encoder-decoder attention is used in models like the original Transformer (e.g., for translation tasks), but not in GPT or BERT.
Training
Zero-shot & Few-shot
- It seems they are also concepts not only in prompting as the following source links, but also in fine-tuning means that the model hasn’t been fine-tuned on the new task and is instead evaluated on the new task directly without any task-specific adjustments.
Examples in Prompts: From Zero-Shot to Few-Shot
What Are Zero-Shot Prompting and Few-Shot Prompting
Reinforcement Learning
Q-learning
Geeksforgeeks Reinforcement Learning
RLHF
- RLHF
- PPO
- DPO
Is DPO Superior to PPO for LLM Alignment? A Comprehensive Study
ICML 2026 Cited by 244
Direct Preference Optimization:Your Language Model is Secretly a Reward Model
NeurIPS 2023 Cited by 7219
Local Deployment
Ollama
- Download the ollama on https://ollama.com/.
- Open a terminal and input ‘ollama –version’ to check if the downloading is successful.
- Download the LLMs by inputing ‘ollama pull llama3’
- Open a teminal and input:
curl http://localhost:11434/api/generate -d '{ "model": "llama3", "prompt": "Why is the sky blue?"}'to try to interact with the LLMs.
- There is also a UI interface in ollama in which users can talk with the LLMs, including the pulled ones, in a breifer way.
Run LLMs Locally: 6 Simple Methods
vLLM
Performance vs Practicality: A Comparison of vLLM and Ollama
OpenClaw
-
iwr -useb https://openclaw.ai/install.ps1 iex - choose GLM https://bigmodel.cn/apikey/platform
- choose feishu https://open.feishu.cn/app/cli_a9519a06e4b85cdd/baseinfo
- openclaw gateway
- openclaw gateway status
- openclaw dashboard gateway: http://127.0.0.1:18789/
- openclaw config